More container talk for HPE Cloud 28+
More container talk for HPE Cloud 28+
I spoke to UKFast on 7th March about some of the business benefits customers see with from container technologies
HPE's @pressedontech explains why businesses are embracing #container technology. #CEE18 #Cloud28+ pic.twitter.com/ZKOSp7nhpd
— TechNative (@TechNative) March 19, 2018
I spoke with UKFast on 14th March about In Memory compute instead of disk based storage and the performance benefits this brings
#HPE's Chief Technologist @pressedontech spoke to us about trends in #MachineLearning & predictive #analytics. #AI #Cloud28+ pic.twitter.com/ie745X5otA
— TechNative (@TechNative) March 20, 2018
I spoke with UKFast on 14th March about Predictive Analytics
#HPE's Chief Technologist Rob Reynolds explains how #SuperdomeFlex provides "super fast storage" for #SQLServer. #InMemoryComputing #HPEMSFT #Cloud28+ pic.twitter.com/VXWwEdzEKV
— TechNative (@TechNative) March 22, 2018
Hi Rob,
This is not important just some points I was thinking about during the team call this morning. You always have an interesting point of view so I thought I’d share and get your feedback.
In particular the discussion about how long AWS would need to survive without another outage in order to create 5x9s availability. It occurred to me that it was a completely fatuous measurement because I believe we’re at that Dev/Ops cross roads where we can no longer depend on hardware to save us from data loss. Looking at the AWS Service Level Agreement it basically states that “we won’t charge you if we can’t provide a service” to quote them directly they say “AWS will use commercially reasonable efforts…” which is not a commitment to service that I’d like to have my salary dependent upon.
Over the past 20 years or so there has been a creeping paradigm of hardware resilience for example RAID on disks, remote replication, clustered failover, hardware error checking and many other such technologies that have allowed developers to ignore resilience in their systems. But in the world of cloud, all of the resilience that has been baked into hardware is now gone. If you don’t own your own datacenter and haven’t ensured resilience and failover capability then, as a developer, you’d better start thinking about it again because your service provider isn’t go put it in, it would make their whole charging model unsupportable.
There is evidence that developers are already thinking about this and have done something about it. I’m probably not on the bleeding edge of ideas here. For example one of my bug bears with Docker is its lack of state. But in an environment where there isn’t any resilience it makes absolute sense not to preserve any state, if it doesn’t have a state then you can start another session on another piece of hardware anywhere you like with minimal disruption to your applications. Complete statelessness is hard to achieve, so somewhere there has to be some DB which needs hardware resilience.
I think my point really is that we have to fundamentally change our thoughts about the way systems work. Talking about 5x9s resilience is no longer relevant.
Comments, thoughts, ideas?
so I replied:
Hi Simon
I’m seeing a couple of data points as the market view on public cloud matures.
There’s a growing market for tools and professional services for public cloud to help customers constrain their costs. I was amused to hear that Amazon itself manages a 2nd hand market on reserved instances (RI’s) where customers can resell their unused RI’s to other AWS customers to recoup some of those costs. And there are consultancies that help customers either buy those RI’s from the marketplace at the lowest price or sell their RI’s at the highest price.
Seems to conflict with the idea that cloud is cheap.
The opportunity risk piece comes from the fact that organisations can implement products faster with public cloud without going through the CAPEX procurement cycle. And if those new products or services fail then they aren’t left with infrastructure they don’t need. So cloud isn’t a cheaper way to deliver infrastructure. But a faster way to deliver it in the short term.
How is that related to your point above? I think it’s examples of how the perception of public cloud is changing. I personally like to take the long view. When TV’s were first introduced they would be the death knell for the cinema. When the internet came around it would be the end for books and newspapers. The introduction of new technology always predicts the supercedence of existing tools. Don’t get me wrong; CD’s are no more (although interestingly vinyl lives on), and newspapers are in a dwindling market. But the cinema experience is fundamentally different to the TV experience. The book experience is different to reading websites.
Those examples show that different technologies enable us to consuming things in different ways. There’s no doubt the x86 server market is in decline. But that’s from a position where 100% of technology is on premises. As we learn more about the benefits of public cloud we learn that it also has drawbacks in the way it’s been implemented. I therefore believe that a balance will be found where some workloads will necessitate being within a customer’s physical location. And some will benefit from being hosted with a hyper-scale cloud provider. IT will be consumed in a different way. I don’t believe on-premises infrastructure will go away though.
I childishly take some glee from AWS outages. I take umbrage from the assertion that Infrastructure is irrelevant and the developer is the new king maker. Software Development is hard. Infrastructure is hard. So when AWS or Azure or AWS (again) has an outage it brings that reality into stark relief. The glee I get is from the humble pie being eaten by so called pundits who portray cloud as the next evolution of technology when really it’s the emperor’s new clothes. It’s somewhat unfair to expect developers to be experts in how to make their code run efficiently, be well documented, modular, deliver services to market quickly – and then also be experts on high availability, disaster recovery, data lifecycle management, etc. etc. etc. Both skills are important. But are fundamentally different. To expect public cloud to be able to deliver the same service without the same level of expertise is patently ridiculous. It won’t achieve 5x9s. But then I don’t believe it should. It’s something different. And should be architected and understood as such.
Tying the various threads together, I strongly believe there is a use case for agile, devops style methodologies. And an agile infrastructure to support it. But I firmly believe that one size doesn’t fit all and infrastructure architects and expertise has a strong role to play in conjunction with software development expertise to deliver the right solutions for the future.
Well that was a long winded response. I can see a copy and paste blog post coming J
A question from a colleague– do I think everything will go containers? Our conversation kind of got lost in a conversation around devops and version control. But we had a good and healthy debate
To try and answer his question , my view is that Containers are a solution to two problems:
For those problems, containers are great. But that’s not every use case. Banks selling mortgages is a relatively static requirement, heavily regulated. The bank may take on more mortgages but they don’t have the need to iterate quickly. That requirement is to have an architecture that supports speed, resiliency and high data processing. Walmart might need to iterate quickly to get an app to market to differentiate against Target. But the core requirement to take payments for products in store and for the sale of product to be reflected in the stock replenishment system is a static requirement.
For the benefits they bring, they will bring other problems (integration into existing monitoring dashboards for performance, errors, etc is a massive ops issue that devs don’t consider for example). If an organization can see past wanted to use the latest shiny thing and can match an infrastructure + software solution to their actually need – I don’t see containers replacing everything.
But then maybe I’m an out of date old guy.
Earlier this year I built a Bitcoin mining project with my old Raspberry PI. Even though it’s the older model, the USB ASIC offloads all of the CPU processing so it’s an ideal project for the older PI (there’s a whole separate thread around whether we really need the extra CPU horsepower in the newer PI’s. Although a benefit is that the old model B’s will probably get a lot cheaper on ebay)
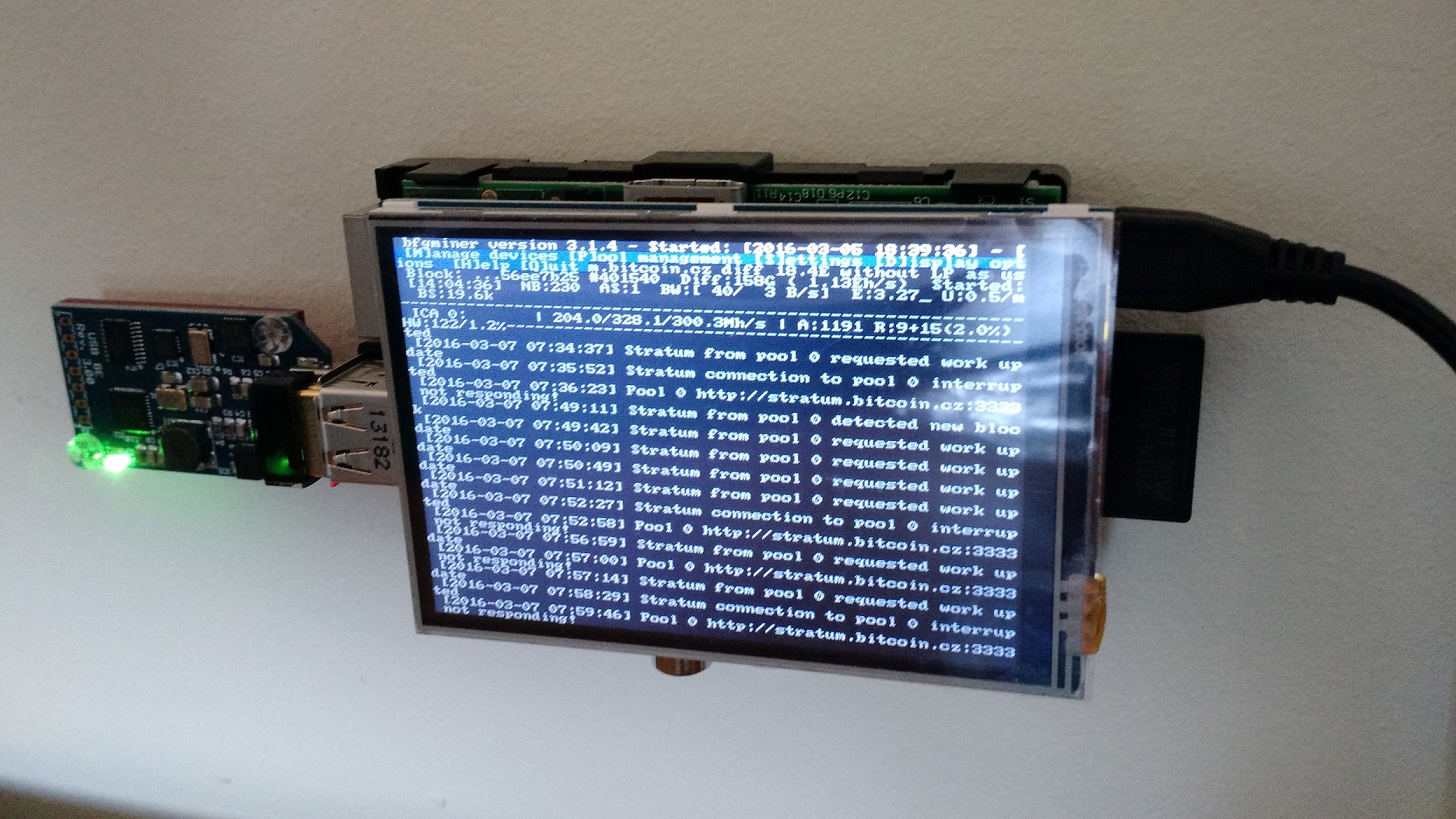
Buyer Beware – I did this about 4 weeks ago and had loads of fiddling to make it work. I’ve gone back through bash histories to document everything I did. If I’ve missed anything then that’s my excuse. But feel free to drop me a line if you’ve tried stuff and it doesn’t work.
I installed a clean version of Jessie to start the project. But I had to do a fair amount of fiddling to get the screen up and running. Most of the effort in getting this project working was around getting the screen to a) work, and b) stay on. As such I thought I’d document it here to see if it helps anyone.
The screen I picked up is from Amazon – described as a “Makibes® 3.5 inch Touch Screen TFT LCD (A) 320*480 Designed for Raspberry Pi RPi/Raspberry Pi 2 Model B”. The back of the screen says “3.5inch RPi LCD (A) V3 WaveShare SpotPear”.

I think the Makibes thing is a rebrand as most of the google search results for the errors I was getting were brought up the WaveShare screen. As per the comments in the Amazon page, this link many found helpful. It got me to the point where I could manually load the modules. But it didn’t stay persistent over the reboot. As per the page I just linked to (and I’m just copying and pasting his work here, check out the link for the full info), I could get the screen working with a modprobe
modprobe flexfb nobacklight regwidth=16 init=-1,0xb0,0x0,-1,0x11,-2,250,-1,0x3A,0x55,-1,0xC2,0x44,-1,0xC5,0x00,0x00,0x00,0x00,-1,0xE0,0x0F,0x1F,0x1C,0x0C,0x0F,0x08,0x48,0x98,0x37,0x0A,0x13,0x04,0x11,0x0D,0x00,-1,0xE1,0x0F,0x32,0x2E,0x0B,0x0D,0x05,0x47,0x75,0x37,0x06,0x10,0x03,0x24,0x20,0x00,-1,0xE2,0x0F,0x32,0x2E,0x0B,0x0D,0x05,0x47,0x75,0x37,0x06,0x10,0x03,0x24,0x20,0x00,-1,0x36,0x28,-1,0x11,-1,0x29,-3 width=480 height=320
modprobe fbtft_device name=flexfb speed=16000000 gpios=reset:25,dc:24
If your screen matches the description above and that works, then happy days. Here’s what I ended up doing to make it persistent post reboot:
First off, if it isn’t already enable SPI in the raspi-config tool
in “/boot/config.txt” I’ve appended the following lines
Enable audio (loads snd_bcm2835) dtparam=spi=on # dtoverlay=ads7846,cs=1,penirq=17,penirq_pull=2,speed=1000000,keep_vref_on=1,swapxy=0,pmax=255,xohms=60,xmin=200,xmax=3900,ymin=200,ymax=3900 dtoverlay=ads7846,speed=500000,penirq=17,swapxy=1 dtparam=i2c_arm=on dtoverlay=pcf2127-rtc # dtoverlay=w1-gpio-pullup,gpiopin=4,extpullup=1 device_tree=on
/boot/cmdline.txt passes parameters to the bootloader. I’ve appended a couple of lines to make the console appear on the SPI TFT screen instead of the default HDMI. Also, the console blanking is disabled
dwc_otg.lpm_enable=0 console=ttyAMA0,115200 console=tty1 root=/dev/mmcblk0p2 rootfstype=ext4 elevator=deadline fsck.repair=yes rootwait fbcon=map:1 fbcon=font:ProFont6x11 logo.nologo consoleblank=0
/etc/modules now looks like this:
snd-bcm2835 i2c-bcm2708 i2c-dev
Something I didn’t pick up from other forum posts and blogs is the config required to auto load modules on bootup. So I created /etc/modules-load.d/fbtft.conf to effectively do what modprobe is doing from the command line
spi_bcm2708 flexfb fbtft_device
Console Blanking is apparently a bit busted in Jessie, so /etc/kbd/config needs the following settings (they aren’t next to each other in the file so you’ll need to search through it to make both edits:
BLANK_TIME=0 POWERDOWN_TIME=0
And /etc/init.d/kbd needs to look like this (search for screensaver stuff in the file – it’s quite long)
# screensaver stuff setterm_args="" if [ "$BLANK_TIME" ]; then setterm_args="$setterm_args -blank $BLANK_TIME" fi if [ "$BLANK_DPMS" ]; then setterm_args="$setterm_args -powersave $BLANK_DPMS" fi if [ "$POWERDOWN_TIME" ]; then setterm_args="$setterm_args -powerdown $POWERDOWN_TIME" fi if [ "$setterm_args" ]; then # setterm $setterm_args TERM=linux setterm > /dev/tty1 $setterm_args fi
That should get you to the point where your Raspberry PI will reboot and then always use the TFT screen as a display output.
To complete the project I used this USB ASIC to do my bitcoin mining. Amazon is out of stock at the time of writing. However it will give you what you need to search ebay for, etc. This instructables is complete enough that there’s little point me replicating it here. However, there were a couple of additions that I needed to do before it worked and to complete the project.

First off I needed to install some additional packages:
sudo apt-get install autoconf autogen libtool uthash-dev libjansson-dev libcurl4-openssl-dev libusb-dev libncurses-dev git-core
Download the zip file, build and install the code
wget http://luke.dashjr.org/programs/bitcoin/files/bfgminer/3.1.4/bfgminer-3.1.4.zip unzip bfgminer-3.1.4.zip cd bfgminer-3.1.4 make clean ./autogen.sh ./configure make sudo make install
The last part of the project is a total hack as I ran out of steam with my enthusiasm. It’s pretty insecure and absolutely not best practise, etc. etc. But I got lazy, and it works. I’m sure you can make something better given a few more brain cells. First off, make sure the pi boots into console mode and not x windows.(option number 3 in raspi-config). Then choose option
B2 Console Autologin Text console, automatically logged in as 'pi' user
Then I created the following script – /home/pi/login.sh
#!/bin/bash # /usr/local/bfgminer-3.1.4/bfgminer -o stratum.bitcoin.cz:3333 -O username.password -S all
Every time it boots, the Raspberry PI automatically logs in as the ‘pi’ user. And everytime the pi user logs in, that script is run. Totally insecure. And I’ll probably go back and fix it when I’ve got a spare 30 minutes. But it works for now

What you need to install Windows 10 IoT on the Raspberry Pi 2
First thing to think about it to understand the Raspberry Pi 2 is different to the original Raspberry Pi

The form factor is different. If you have a Raspberry Pi and are upgrading, you’ll want a different case. Second point is that you are installing a different OS so you’ll need to consider whether your hardware is compatible. For my Raspberry Pi running Raspian I use an old Buffalo WLI-UC-GN. I just pulled this out of my spare parts bin when I setup Raspian. In hindsight I probably purchased the Buffalo card because it was Linux compatible. The Windows 10 IoT Hardware Compatibility list is here. From that list I purchased this TP-LINK Wireless USB Adapter and it worked first time for me.

For the case I picked up this case and it has a couple of nice features:

The base is full of holes which helps airflow.

The case also has a middle layer so you can have most of the unit protected but also expose the the expansion ports. That’s more by accident than design – I was just looking for a cheap case. But I’m quite happy with what turned up so thought it was worth sharing.
Once you’ve got the hardware ready you’ll want to install the O/S. For this you’ll need an Micro SD card and the Windows IoT Dashboard. Go to Microsoft’s Get Started with Windows IoT and scroll down to the “Set up a Windows 10 IoT Core Device” section to download the software.
Fire up the software and the default page is the “Set up a new device”.
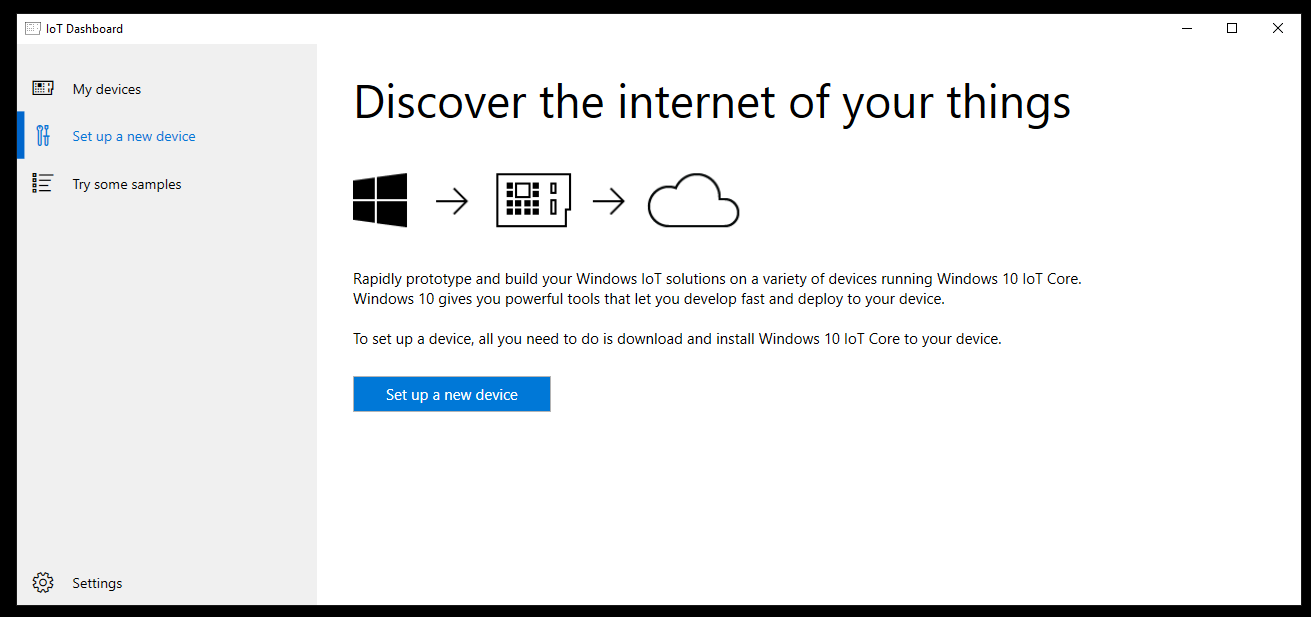
Insert an SD card and click the “set up a new device” button.
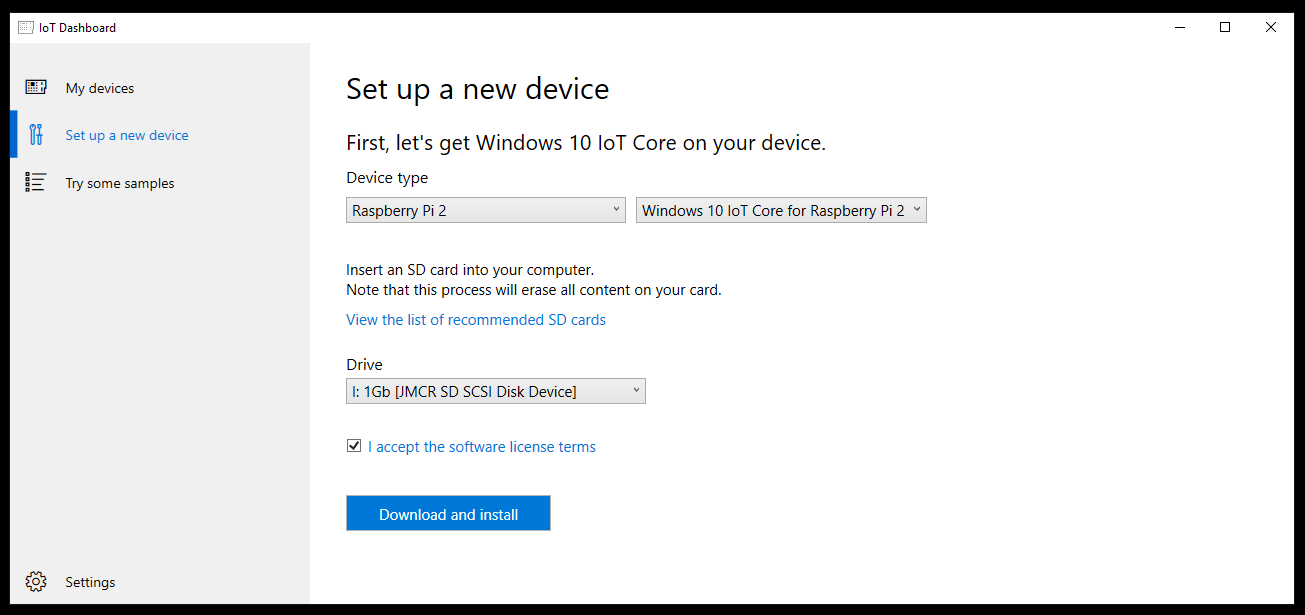
The tool will then download the software and burn the image to the Micro SD card. Insert the Micro SD into the Raspberry PI and power it on. You’ll want to be on the same Ethernet network as the Raspberry PI because you configure the device over the network. The difference between the Windows 10 configuration and the Raspbian configuration is that I can plug a keyboard and mouse into the Linux setup and configure networking from there. Windows assumes this is a device purely for Internet of Things so all configuration is done over the network from a PC.
Note that the Micro SD card is underneath the PI 2, not on top like the first Model B.

After a while you should see the minwinpc appear in the “My Devices” section of the IoT
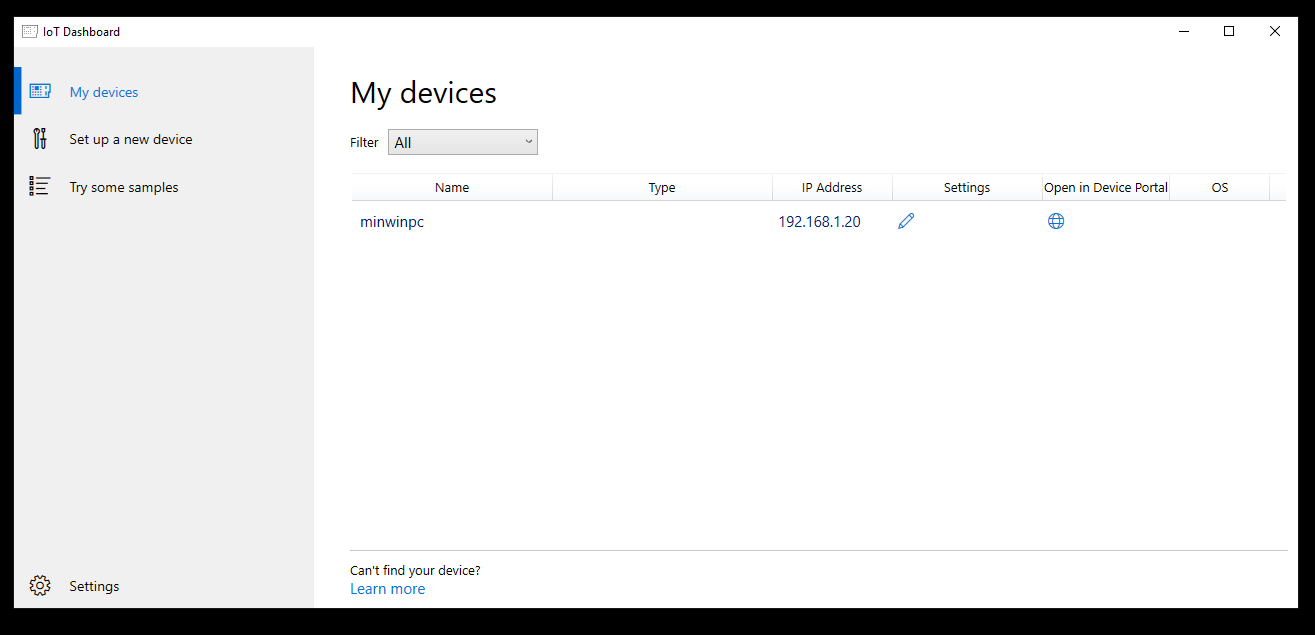
Click on the Globe logo under “Open in Device Portal” and it will launch a web browser. I’m only going off my own experience but whilst I generally like the Microsoft Edge Browser, it didn’t really like the Windows 10 IoT device configuration portal. Silly things like the buttons didn’t seem to press when I was trying to get it to do things. Chrome didn’t seem much better. I had the best results with Internet Explorer 11. YMMV
As you can see from the previous page, my Raspberry PI was DHCP’d the address 192.168.1.20. Therefore the login page is http://192.168.1.20:8080/.
Default username is
Administrator
Default password is
p@ssw0rd
Note the ‘@’ and the zero instead of the letter ‘o’
Now you can see the configuration web page where you can setup the Raspberry PI. If you’re security conscious or running on a LAN with other users, then you should change the default password. And probably change the name of the Raspberry PI from ‘minwinpc’ to uniquely identify your device. 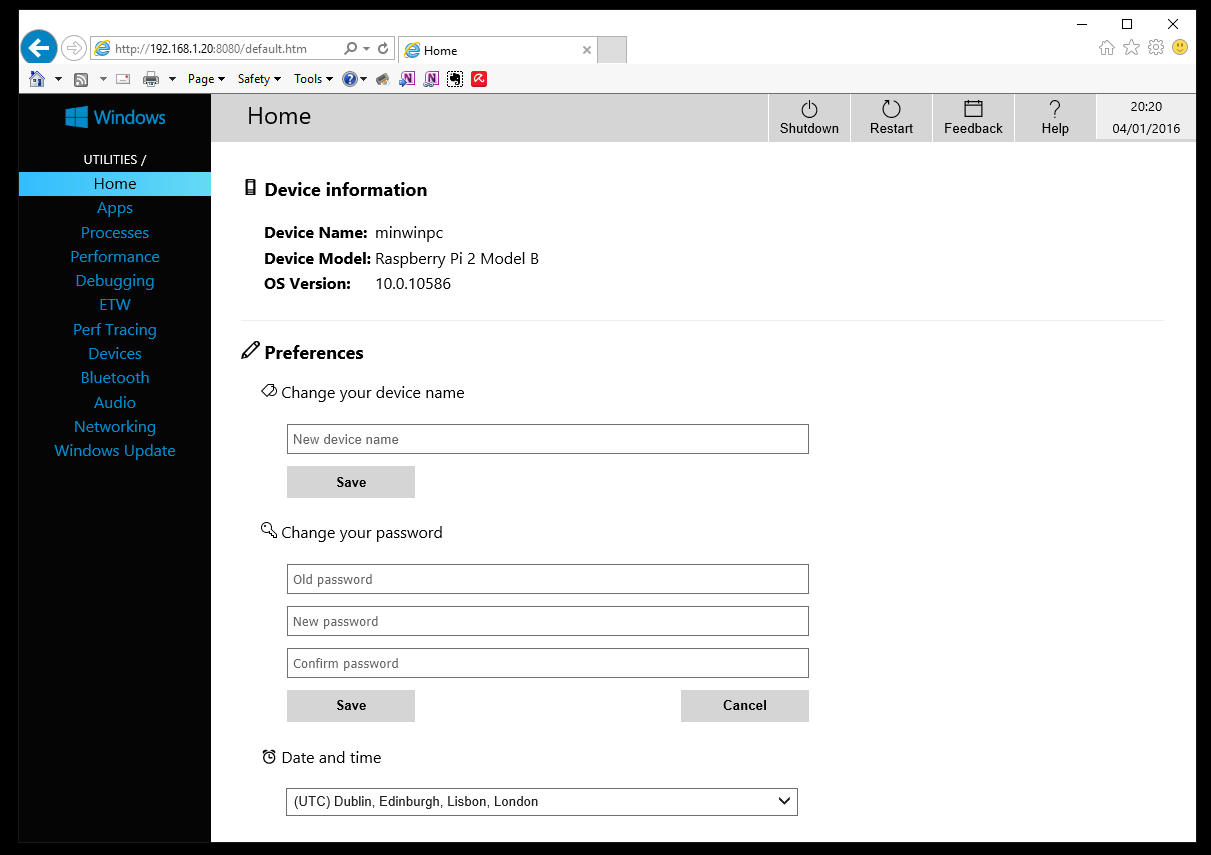
In the Networking page you can then configure the wireless settings:
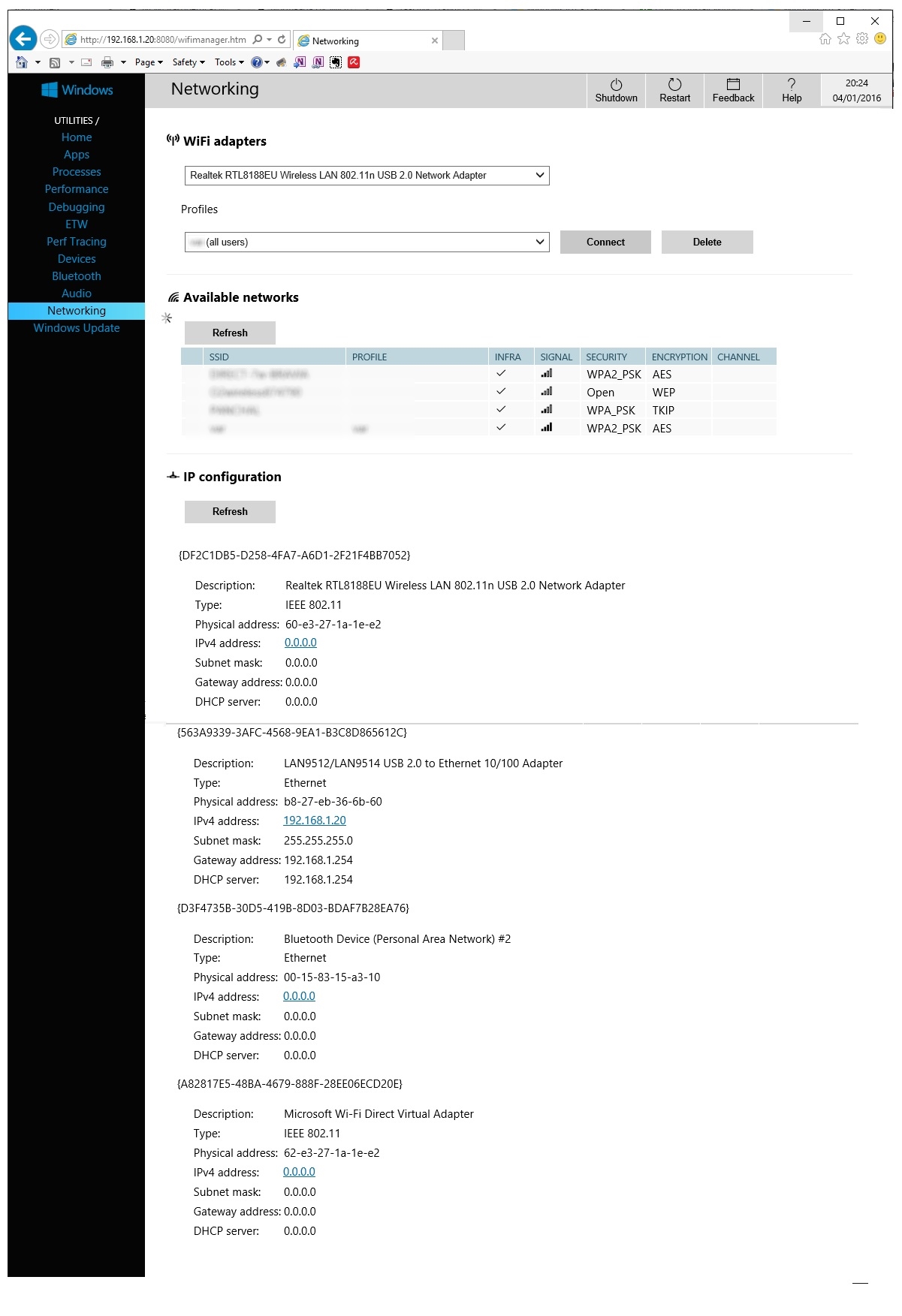
Now you should have a Raspberry PI2 running Windows 10 IOT. Enjoy
Here is how to get the Real Time Clock (RTC) for the X100 Raspberry PI expansion board working in Jessie. Much of the information I found was out of date or for older versions of Raspbian. To check out which version of the expansion board you have, there’s a decent write up on Sainsmart. My X100 Board on my original Model B looks like this

There are instructions on that SainSmart link for getting the different components of the expansion board up and running, including the real time clock. However they’re horrendously out of date, including the suggestion to install version 3.0 of the Linux Kernel. A bit of detective work shows that the rtc on the X100 expansion board is actually the RasClock. (you can tell because the Sainsmart page has copied AfterThought’s instructions for setting up “Setting up on old version of Raspbian”
It wasn’t massively clear from their instructions what I needed to to do to get the clock working. A bit fiddling got me the following steps:
1. Check which overlay you have:
# ls/boot/overlays/
2. Follow the Afterthought Instructions (quoted here for convenience)
If you see the file /boot/overlays/i2c-rtc-overlay.dtb. To enable this add the following line to /boot/config.txt:
dtoverlay=i2c-rtc,pcf2127
If you see the file /boot/overlays/pcf2127-rtc-overlay.dtb. To enable this add the following line to /boot/config.txt:
dtoverlay=pcf2127-rtc
Edit the file /lib/udev/hwclock-set
if [ -e /run/systemd/system ] ; then
exit 0
fi
--systzNow reboot your PI
3. Getting and Setting the time
The first time you use the clock you will need to set the time. To copy the system time into the clock module:
sudo hwclock -w
To read the time from the clock module:
sudo hwclock -r
To copy the time from the clock module to the system:
sudo hwclock -s
On my system, it looked like this:
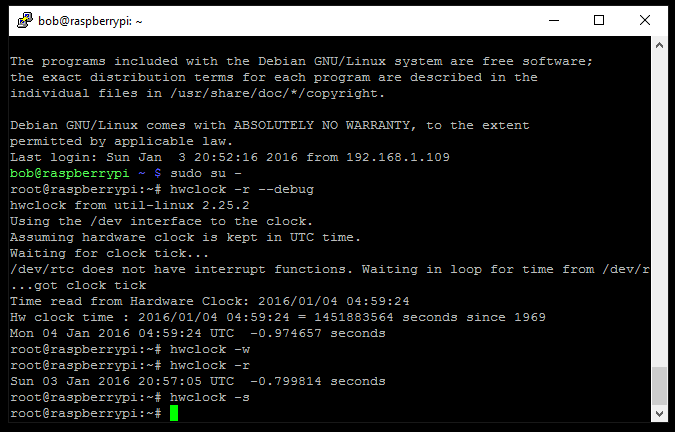
I did also enable the I2C and SPI bus’s on the PI during this process. I don’t think that actually affected the RTC but maybe something to have a look at if yours isn’t working.
There are so many cloud options today it can be baffling. So over the next few pages were going to try and break it down a bit to explain what the different options are, and help with the decision process for each option.
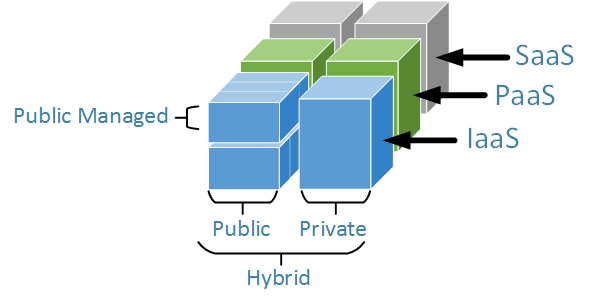
IaaS is typically subdivided into two clear components; Private Cloud and Public Cloud. We have an overview of IaaS and Private Cloud here.
The elevator pitch is Infrastructure as a Service enables the automatic provisioning of operating systems onto physical or virtual hardware by Orchestration Software. Private Cloud uses infrastructure within an organisations data centre. Public cloud uses the infrastructure in a provider’s data centre. And Hybrid Cloud deploys some systems locally, and some in the public cloud. Decisions on location will be driven by internal security policies, external regulations and technology constraints such as application latency requirements
IaaS also provides the option of self-service allowing users to request their own infrastructure without IT admins lifting a finger. And it has the option to charge back individual business units or cost centres for what they are using
The key benefit of cloud technologies is around doing things in a new and different way. Being blunt, Infrastructure as a Service is the lowest common denominator. It lets you do the stuff you’ve always done in more efficient and flexible ways. However as our intro to Infrastructure as a Service highlights, cloud isn’t just a technology change but a people and process change as well. As such it has other benefits in terms of getting an organisation better prepared for the other cloud options.
Here the provider will provide additional components on top of the operating system. So for example Azure has Azure websites and Azure Cloud Services. Here you don’t need to install the Web Server role into IIS. All you need to do is create your code and Microsoft does the rest. The flipside of this is that Microsoft specify what they support. The supported languages for Azure Websites are .Net, Java, PHP Node.JS and Python. Want to code in Perl? Ruby? Go? You’re out of luck. You’re also restricted by the versions of languages supported
| Language | Versions | |||
| .net framework | 3.5 | 4.5 | ||
| PHP | 5.3 | 5.4 | 5.5 | |
| Java | 1.7.0.51 | |||
| Python | 2.7.3 | 3.4 | ||
But that’s not necessarily a bad thing. It lets developers focus on developing code and removes the concerns about scaling infrastructure, patching infrastructure and software and lets things happen faster with less intervention
SaaS is the last model for Cloud. Here all your paying for is a license to use the software. That usually (but not exclusively) means accessing that software through a web browser. Typically cited examples are Salesforce.com, Gmail, Dropbox, etc. Here you have a generic service that’s the same for everybody. Good candidates for SaaS are functions where your company adds no value. Salesforce is a great example here because the CRM functions within organisations aren’t where they add value. Managing sales, managing customers, that’s a relatively generic process. By selecting SaaS products organisations are able to focus their IT resources on the activities
In this diagram you have the components of an IT system.
It’s very high level but you can see
Each of those components has a cost associated with it’s complexity. Remember back to the SaaS description where the use case for SaaS is to pick something generic that isn’t unique to your organisation? That’s the key decision point as to how you should host your technology. Infrastructure as a service sounds like a low rent commodity option. However there may well be unique parts of the product your organisation sells that won’t fit neatly into a Platform as a Service model. It need specific coding languages, specific configuration on the server to deliver whatever it does. The further up stack you go, the more personalisation you lose. Conceptually the technology products that are unique to your organisation are probably better suited to IaaS. Systems you need to keep your business going but are something everyone uses (email, CRM, etc) are better options for SaaS. And PaaS sits somewhere in the middle.
Also think about the industry sector you work in. There may be regulations about where you host your data so checking out where the cloud provider has their datacentre’s is important. Or more likely that becomes a decision point on whether to go public or private cloud.
Investigate application complexity. If a legacy application has been coded with the expectation it’s on a high speed LAN, then moving the servers out onto the internet probably isn’t a good idea.
Hopefully now you’ve got a better idea of what the different cloud technologies are and which might be suitable for your workloads. There isn’t a one size fits all and a lot of the decisions still require judgement. However you’ve got the guidelines here on how things work and that should influence your thinking on how you start planning the deployment of your systems going forward.
Remember, the cloud is just someone else’s computer.